

前言:史丹佛大學AI報告很有趣,所以整理相關內容與我的想法(藍色)。
人工智慧在某些任務上勝過人類,但並非在所有任務上
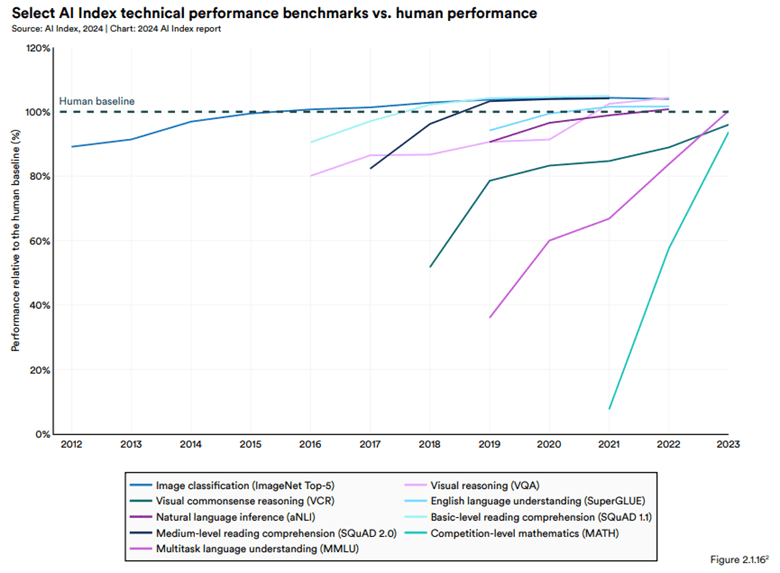
以人類作為基準線比較AI在不同技術的性能測試,發現大多數AI性能隨時間快速提升,到2023已經接近甚至超越人類水平,以下是達人類水平時間軸:
- 2015~2016:圖像分類(ImageNet Top-5)和視覺推理(VOA)最早達到人類水準。
- 分析式AI蓬勃發展,大舉運用於ADAS、物聯網、工業自動化…等。
- 2020年前後:英語語言理解(SuperGLUE)和自然語言推理(aNLI)等語言任務。
- 2020年前後,NVDA強調用於語言相關的應用大幅提升算力需求,當時的Google翻譯也有顯著進步。
- 2022年開始:多模態語言理解(MMLU)的AI性能在開始超越人類,反映了多模態AI技術的快速發展。
- OpenAI 2022/11 發布引爆LLM熱潮,所有資本往GenAI集中。
- 閱讀理解(SQuAD 1.1/2.0)和數學運算(MATH)等更複雜的任務,AI系統的進步也很顯著,但截至2023年仍低於人類水平。
- 廠商仍在致力於更全能的助理,以過去經驗來看,將很快達人類水準。
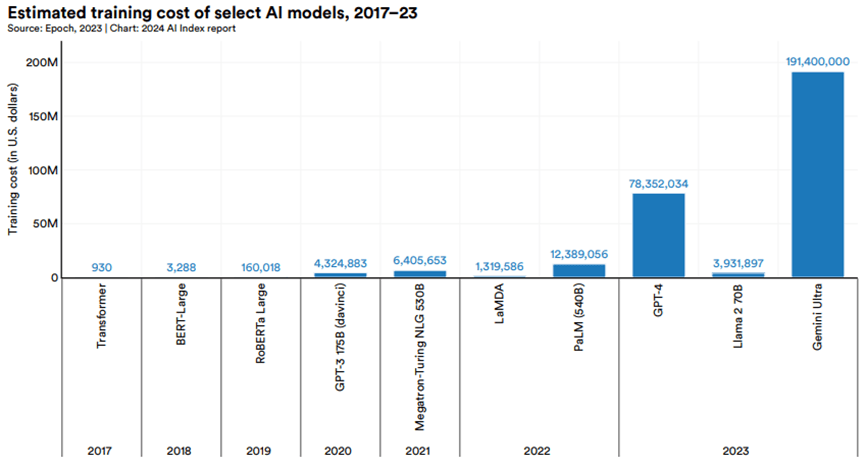
大模型的訓練成本大幅提高,呈現多個數量級式暴增
2017年至2023年間部分重要AI模型的估計訓練成本大幅成長。
- 2017年原始的Transformer模型訓練成本約為900美元。
- 2019年發布的RoBERTa Large模型的訓練成本約為16萬美元。
- 2023年的GPT-4和Gemini Ultra的訓練成本則分別高達7800萬美元和1.91億美元。
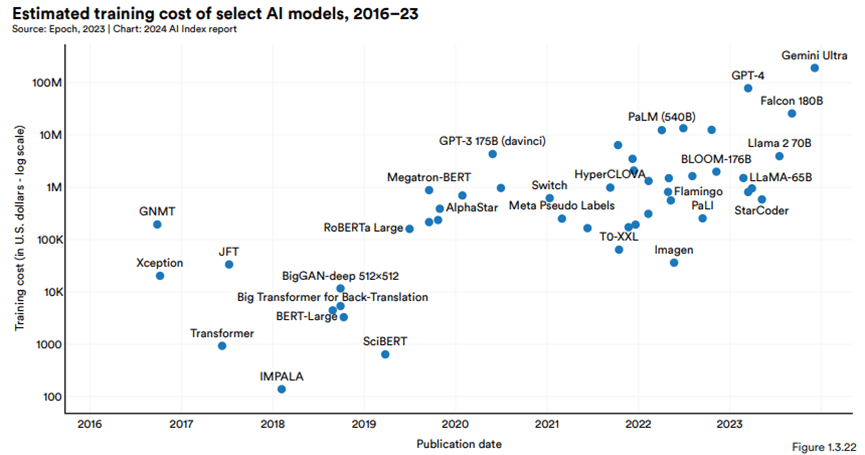
模型訓練成本呈指數級增長:2016年至2023年間AI指數所估計的所有AI模型的訓練成本,隨時間的推移,模型訓練成本明顯的上升趨勢。
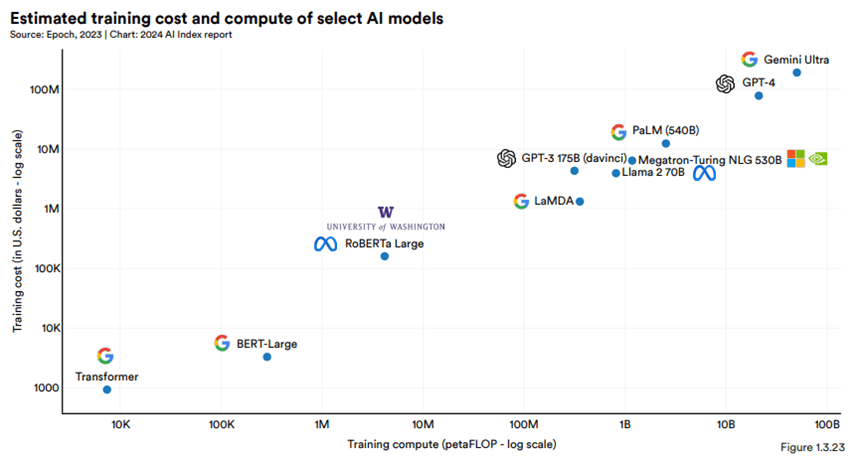
訓練成本與計算需求呈正相關:AI模型預估的訓練成本與其所需計算資源呈現密切相關,計算需求越大的模型,其訓練成本也越高。所以訓練頂尖模型的成本主要來自於大量的計算資源。
面臨痛點:合成數據用於訓練的局限性
儘管使用合成數據可以在一定程度上緩解數據短缺問題,但研究表明,僅使用合成數據訓練的模型會出現模型崩潰(model collapse)現象,生成的內容逐漸變得單一、品質下降。這突顯了繼續使用真實人類數據進行訓練的重要性。
統整:訓練成本增加的主要原因
- 模型複雜度提高、參數量提升。以GPT-4和Gemini Ultra為例,它們的參數量已經達到了數百億甚至上千億的量級。模型參數量的增加直接導致了訓練所需的計算資源和時間成本的上升。
- 但發展至今,持續追逐更複雜、參數量更高的模型是唯一解,因為只有助手更聰明,才有可能觸發更多應用。
- 至於已經可以被落實的應用,則會出現別的分支,試圖降低模型參數量,以降低推論成本(Ex: Github Copilot和Supermaven)。
- 訓練數據量增大:為了訓練出高品質的AI模型,需要大量高質量的訓練數據。隨著模型複雜度的提高,所需的訓練數據量也隨之增加。數據的收集、清洗和標註過程都需要大量的人力和時間成本。
- 這是我原本在去年覺得OpenAI有的護城河,但結果證明,花錢花資源一樣可以做到這點,只是隨著時間推移,如何取到好的data將成為廠商關鍵。(這時候各家自己擁有的數據資源就很重要)
- 計算成本提高:訓練大型AI模型需要昂貴的硬體設施。隨著模型規模的增大,所需的計算資源也隨之增加,導致訓練成本的上升。
目前AI模型發展兩大瓶頸:
- 算力瓶頸:儘管近年來AI硬體的性能不斷提高,但對於訓練越來越大的尖端模型來說,算力仍然是一個瓶頸。這使得只有少數大型科技公司和研究機構才有能力訓練這些模型。報告中提到,學術界在這方面已經明顯落後於業界。
- 數據瓶頸:高品質訓練數據的獲取也是一大挑戰。一方面,隨著模型的訓練規模不斷擴大,對數據量的需求也越來越大。報告中提到,研究人員預測,高品質語言數據可能在2024年就會被用盡。另一方面,單純使用合成數據並不能完全替代真實數據,因為它可能導致模型生成品質的下降。
- 數據的瓶頸也可能是這波算力追逐結束的原因之一。(先前認為是缺電還有沒有好的商業模式)
閉源模型表現得比開源模型更好
封閉模型是指僅限開發者存取的模型(如Google的Gemini),或僅提供有限API存取但未完全開放模型權重的模型(如GPT-4和Claude 2)。相比之下,開放模型(如Llama 2和Stable Diffusion)則完全釋出模型權重,可被任何人自由修改和使用。
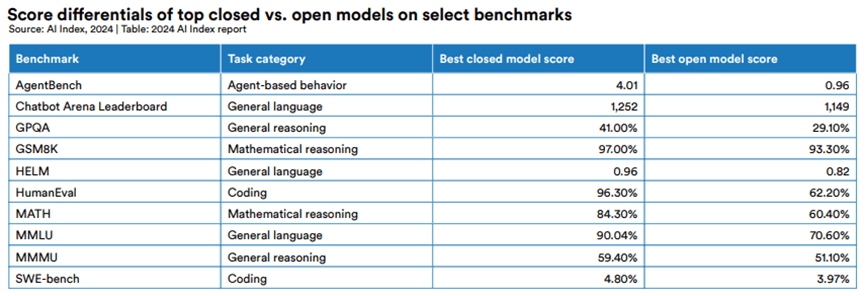
圖表數據顯示,在所有選定的基準測試中,封閉模型的性能都優於開放模型。
以下表格,列出了封閉模型和開放模型在選定基準測試上的得分。
- 第一列顯示了基準測試的名稱和測試的任務類別
- “Best closed model score"列顯示了封閉模型的最高得分
- “Best open model score"列顯示了開放模型的最高得分
下圖比較了封閉模型和開放模型在各基準測試上的性能差距百分比。
- 橫軸:不同的基準測試並按任務類別分組(如編程、數學推理、智能體行為等)
- 縱軸:封閉模型相對於開放模型的性能優勢百分比。
- 藍色條形的高度代表了封閉模型在該基準測試上領先開放模型的百分比。
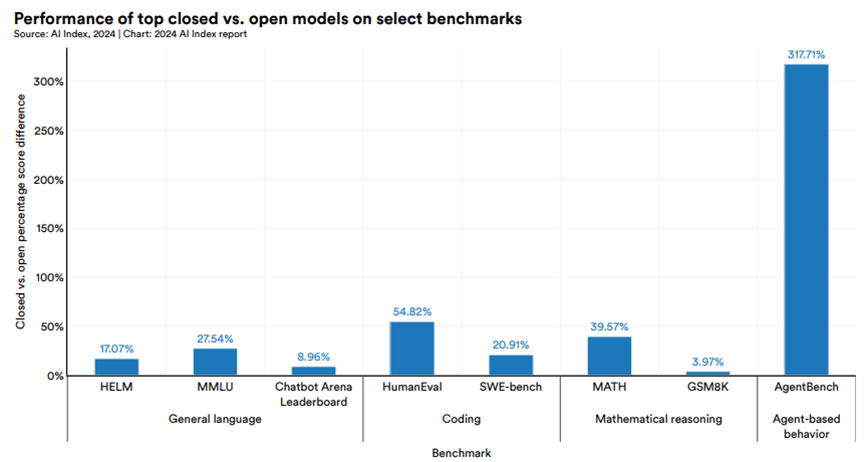
具體來說:
- 在10個選定基準測試中,封閉模型的中位數性能優勢為24.2%。
- 性能差距從數學任務(如GSM8K)的4.0%,到智能體行為任務(如AgentBench)的317.7%不等。在MATH、SWE-bench、HumanEval等編程/數學推理任務上,封閉模型的優勢尤其明顯。
- 可以看出在所列出的測試中,封閉模型的得分都高於開放模型。尤其在AgentBench這類智能體行為任務上,差距最大
造成結果的可能原因:
- 資源投入:閉源模型,如由大型企業開發和維護的模型,通常會有更多的資金和資源用於研發。這包括高性能計算資源、資料收集、和優秀人才的聚集,這些都是開源項目相對較難匹配的
- 數據質量和量:閉源項目可能訪問到更專屬、多樣化或高質量的數據集,這對於訓練更有效的AI模型至關重要。這些數據的多樣性和質量直接影響了模型的泛化能力和效能
- 專利技術和創新:閉源模型可能涉及專利技術或最新的研究成果,這些創新通常不會立即公開。這種獨到的技術創新有時可以顯著提升模型的表現,但這些創新的細節往往不為外界所知
- 客製化和最佳化:閉源項目能夠針對特定的應用進行深度客製化和最佳化。這種針對性的調整有助於在特定的基準測試中取得更好的表現。
- 政策和隱私考量:開源模型需考慮更多的隱私和政策限制,尤其是在處理敏感數據時。這些限制可能會影響模型的訓練和部署,而閉源模型可能能在內部更自由地處理這些問題。
- 換句話說,LLM往前推動還是要頭部大公司進行領導,而且領先優勢是會展現的,因此檯面上現在幾家player都要持續關注,而且他們都得持續拚下去。
- 至於開源,我認為就是想辦法推其他應用,但與過去新技術出來新創蓬勃的狀態相比,會相差很多。(去年就有一直說,GPT推出新功能之後就毀了一堆新創,因為技術迭代太快)
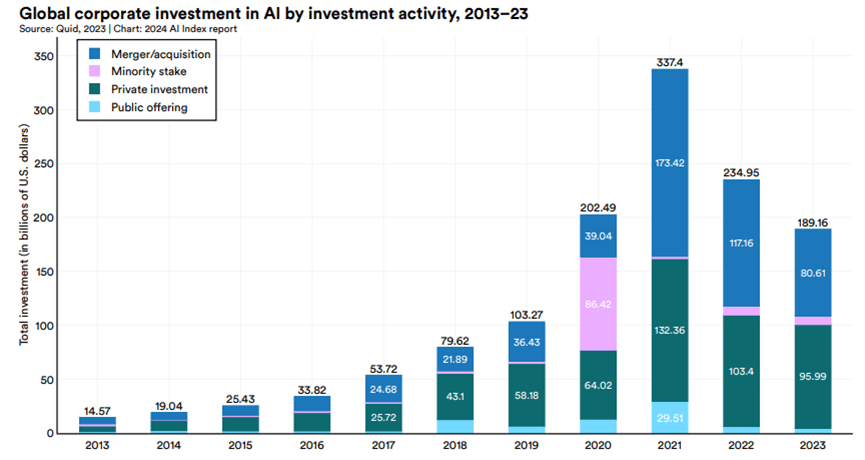
整體AI投資下降,但GenAI投資大幅增加
2013~2023 全球AI投資(包括併購、少數股權投資、私人投資和公開發行):2023年總投資額為1892億美元,較2022年下降約20%,是連續第二年下降。
- AI技術發展以來,投資金額一直是逐年上升,2022之後快速升息可能有澆熄一些火苗,但整體下滑程度還是蠻驚人的。
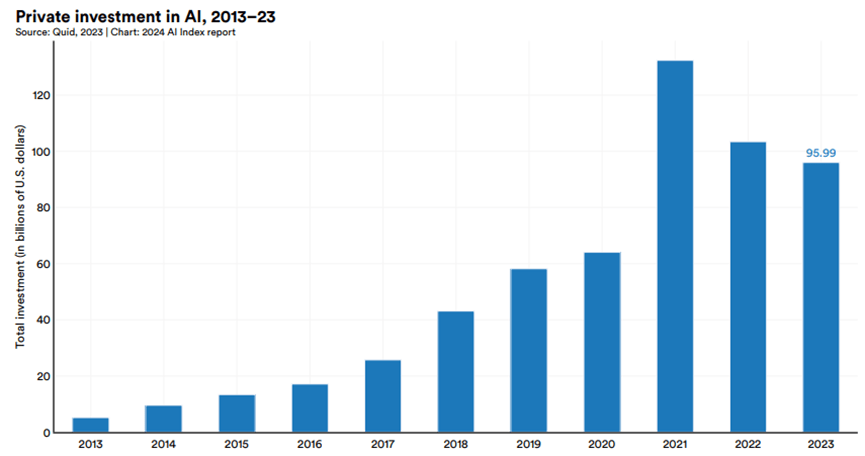
2013~2023 全球AI初創公司的全球私人投資:連續二年下降。
但AI投資中的結構有很大轉變,大幅移轉至GenAI
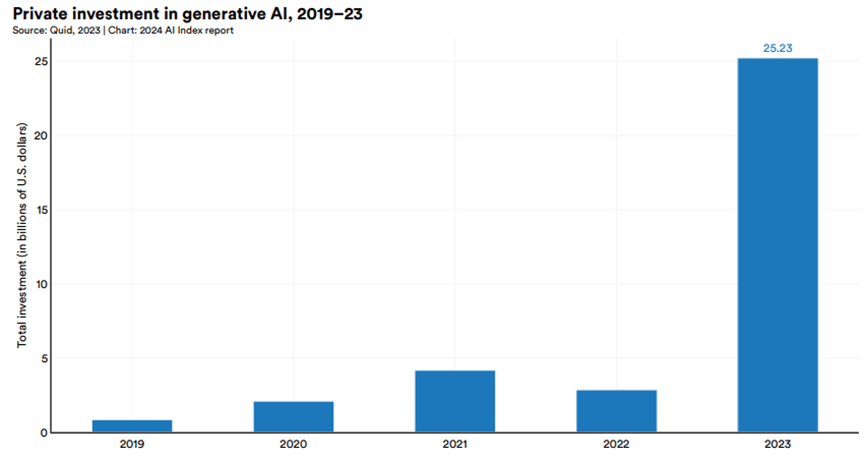
2019年至2023年全球生成式AI領域的私人投資情況:
- 2022年,生成式AI領域獲得約32億美元投資。
- 2023年激增至252億美元,將近2022的9倍,是2019年的30倍。
- 報告指出,2023年生成式AI領域的投資佔全部AI相關私人投資的四分之一以上。(OpenAI、Anthropic、Hugging Face和Inflection等生成式AI領域的主要公司都獲得了大量融資。)
- 儘管整體AI私人投資在2023年出現下降,但生成式AI領域卻獲得了大量投資,呈現出與整體趨勢不同的發展態勢。
美國AI私人投資優勢擴大,生成式AI推出之後尤其如此
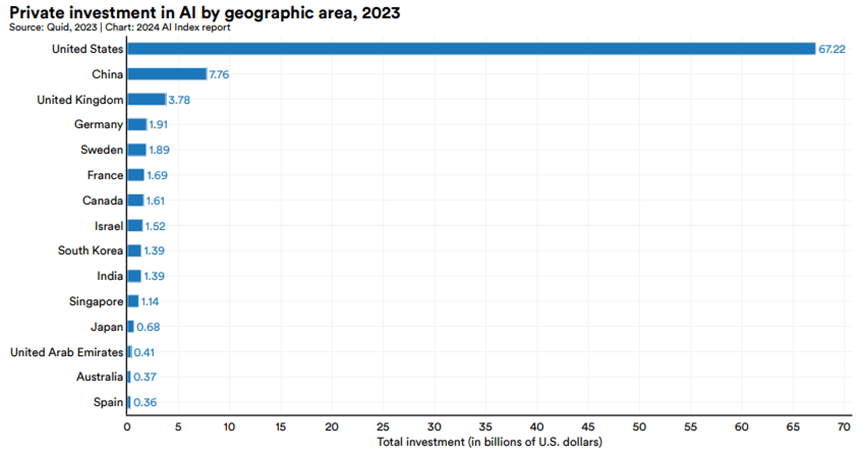
2023年各國/地區的AI私人投資金額。美國以672億美元遙遙領先,是第二名中國(78億美元)的8.7倍,是第三名英國(38億美元)的17.8倍。
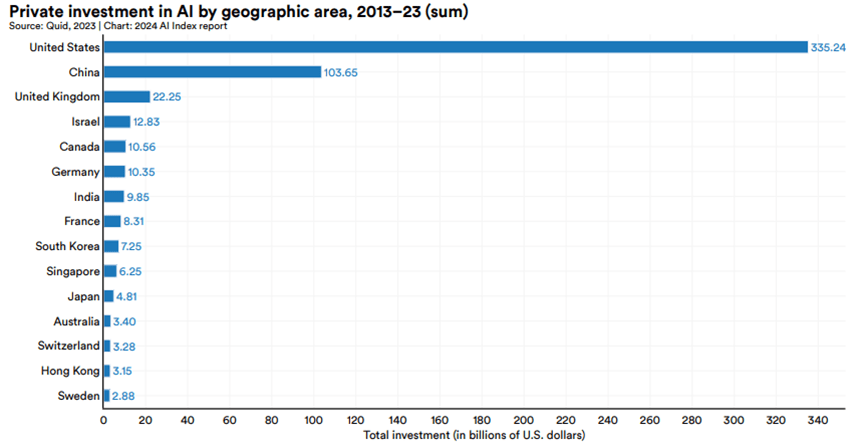
2013年至2023年各國/地區AI私人投資金額的累計情況。美國仍然領先,累計投資額達3352億美元,遠超中國的1037億美元和英國的223億美元。
- 美國與其他地區的差距在過去幾年不斷擴大。2023年美國的投資額增長22.1%,而中國和歐盟卻分別下降了44.2%和14.1%。
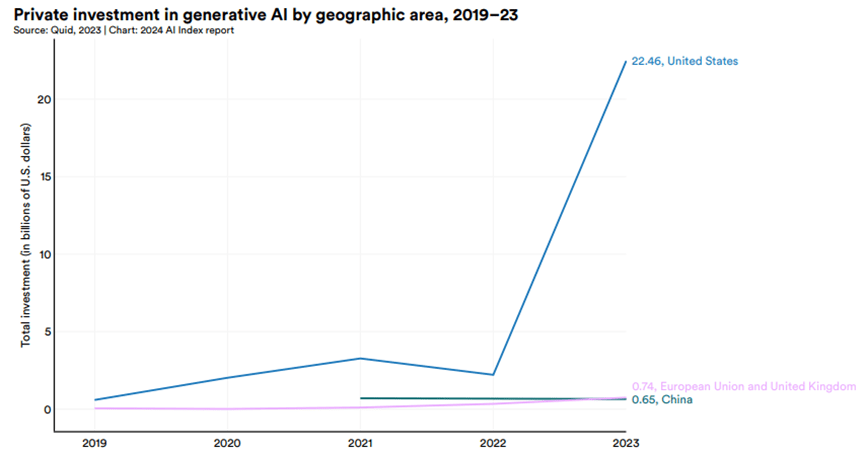
美國在生成式AI的投資優勢更加明顯,2023年美國在生成式AI領域的投資額超過了中國和歐盟的總和:
全球和美國AI相關職位需求下降
- 2014年至2023年各國/地區AI相關職位佔所有職位的百分比
- 2023年,AI相關職位佔比最高的國家是美國(1.6%)、西班牙(1.4%)和瑞典(1.3%)。
- 2022年,AI相關職位佔美國所有職位的2%,2023年下降到1.6%。
- 儘管2023年大多數國家的AI職位佔比均有所下降,但過去五年,許多國家AI相關職位空缺的絕對數量仍然增加。
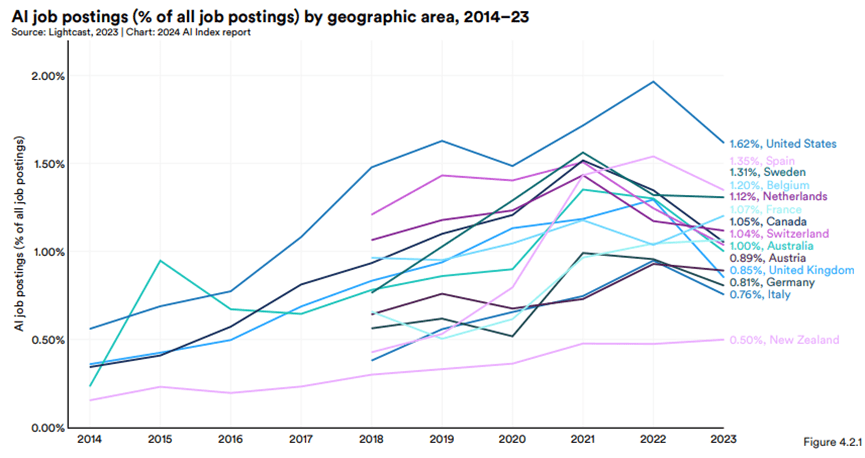
全球AI相關職位需求的整體下降趨勢,尤其是美國的下降幅度比較明顯。
- 2023年需求最高的AI技能是機器學習(0.7%),其次是人工智慧(0.5%)和自然語言處理(0.2%)。
- 儘管總體呈下降趨勢,但機器學習仍是需求最旺盛的技能。
- 與2022年相比,除生成式AI外,其他所有AI技能類別的職位佔比均有所下降。生成式AI的職位佔比增長了10倍以上。
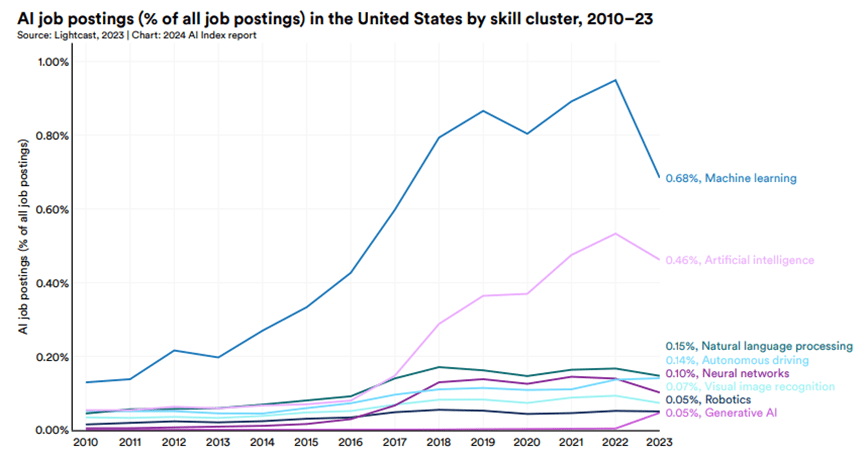
總結整體環境:投資與職缺減少,但是大幅往生成式AI集中
- 生成式AI投資的大幅增加:儘管2023年整體AI私人投資出現下降,但生成式AI領域卻獲得大量投資。生成式AI在2023年佔AI相關私人投資1/4。
- 美國AI私人投資的領先優勢進一步擴大:2023年,尤其在生成式AI,更是拉大了與其他國家和地區的差距。
- 全球和美國的AI相關職位需求下降:儘管AI在各行各業的應用越來越廣泛,但2023年AI相關職位的需求卻出現了下降。
AI是屠龍刀,會用將可大幅提升效率、降低企業營運成本
站在個人角度,將可大幅提升效率(AI不會取代你但是懂AI 的人會):
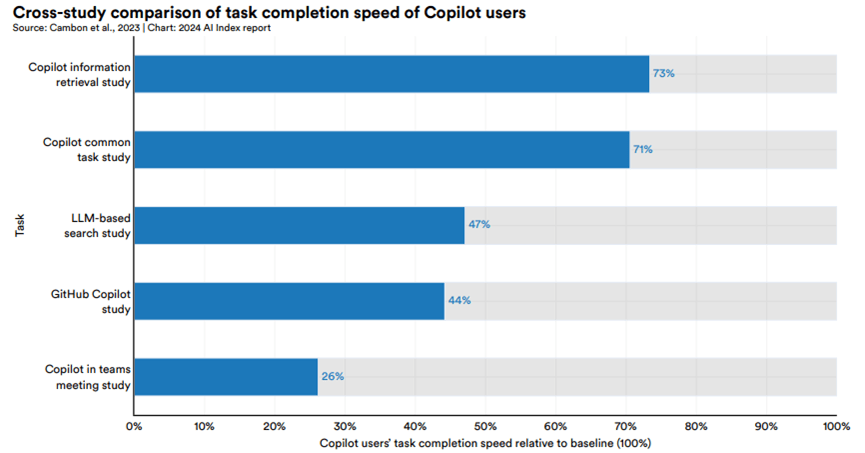
使用Microsoft Copilot或GitHub Copilot的員工與未使用這些AI工具的員工在完成任務速度上的差異:使用Copilot的員工完成任務的速度比未使用的員工快26%到73%。
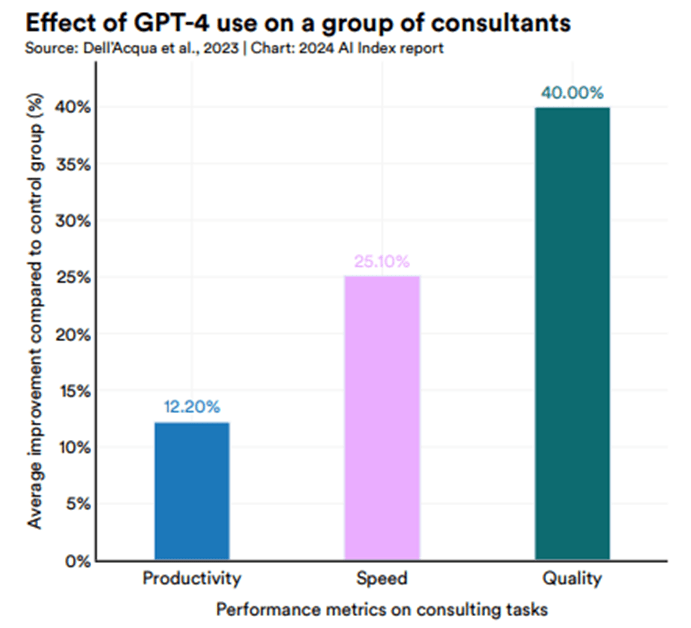
使用GPT-4的員工與未使用的員工在各項任務上的表現差異。
- 在生產力方面,使用GPT-4的員工比未使用的員工提高了12.2%。
- 在工作速度方面,使用GPT-4的員工比未使用的員工提高了25.1%。
- 在工作品質方面,使用GPT-4的員工比未使用的員工提高了40%。
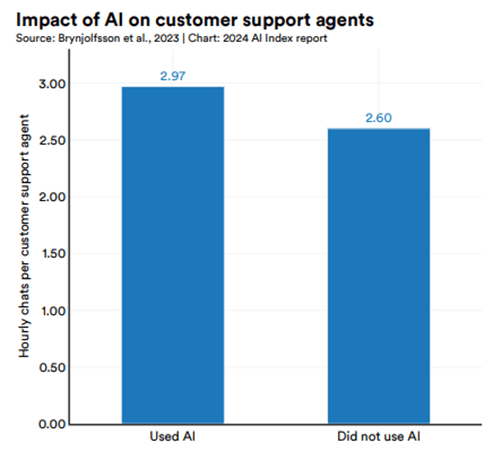
國家經濟研究局的研究結果,比較了使用AI的客服人員與未使用AI的客服人員的工作效率差異:使用AI的客服人員平均每小時處理的電話量比未使用AI的客服人員多14.2%。
個人想法:
- 這些圖表和研究結果都指向一個共同的結論:使用AI工具,尤其是大語言模型如GPT-4,可以顯著提高員工在各行各業的工作效率和工作品質。
- 但報告也提醒,過度依賴AI可能導致性能下降:內容有其中一個研究提到,當招聘人員認為自己使用的是"優秀的AI"(被認為性能卓越)時,他們的表現反而比使用"普通AI"(有能力但會犯錯)的招聘人員差1.08分。研究認為,使用"優秀AI"的招聘人員變得自滿,過度信任AI的結果;而使用"普通AI"的招聘人員則更加警惕,會仔細審查AI的輸出。
- 這把屠龍刀一點有用,但怎麼用?是關鍵!
站在企業角度,將可大幅節省成本、增加收入:
下表展示企業採用AI後,在各業務職能領域實現的成本降低和收入增加情況。
- 2022年,42%的受訪企業報告了因AI採用而降低的成本,59%的企業報告了收入增加。
- 與上一年相比,報告成本降低的受訪企業比例增加了10個百分點,這表明AI正在顯著提高企業運營效率。
- 報告顯示,製造(55%)、服務運營(54%)和風險管理(44%)是受訪企業最常報告成本節約的領域。而在收入增長方面,受益最大的領域是製造(66%)、營銷和銷售(65%)以及風險管理(64%)。

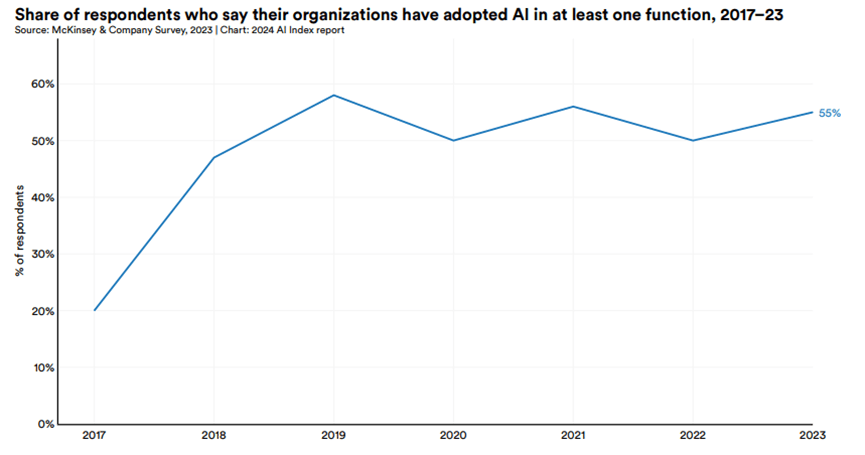
2017年至2023年,企業在至少一個業務部門採用AI的比例:
結論:再次釐清趨勢,並明白GenAI與過去不同之處
- 追逐大模型是必然,參數量將持續呈現指數型成長。
(當有更聰明的助理,才能協助我們做更多事) - 因為算力和資料量的限制,封閉模型的領先優勢可望持續下去。
(學術/政府將很難追上,因此持續關注有投資的MSFT. AMZN. GOOG) - 符合體感的非典型復甦,過去兩年AI投資與職缺其實都是減少的,但比重大幅往生成式AI集中。(就像硬體大幅往NVDA集中一樣,這是在還沒有明確商業模式下必需的結果,但也和過去大多頭環境不同)
- 個人使用AI一定會提升效率、企業使用AI則可降低成本與增加收入。
(但要注意,若過度信任AI效果會更差,因此怎麼使用這把屠龍刀將成為個人競爭力的差異。畢竟AI不會取代你,但懂AI的人會。)

你必須登入才能發表留言。