

因為這段期間都在看上市公司說法,所以找了幾篇有趣的文章,想知道一下業內人士對AI趨勢演變的看法,整理相關內容並將我的看法或補充用藍色顯示。
第一篇有趣的文章:SITUATIONAL AWARENESS: The Decade Ahead
作者 Leopold Aschenbrenner 提到自己曾在 OpenAI 工作,他認為只有灣區 AI 圈子裡的幾百人真正意識到 AGI(通用人工智慧)很快就要來臨,並且會對世界產生巨大衝擊。他聲稱自己是這幾百人中的一員,瞭解 AI 發展的最新進展和走向。(文章發表於 2024/6,作者表示這是基於公開信息、個人想法和一般領域知識撰寫的,代表了他個人對未來 10 年 AI 發展的看法和預測)
人工智慧算力大躍進和智慧爆炸的必然性
從過去演進和計算能力指數成長(OOM)趨勢來推論
作者最大的推論是「根據 GPT-4 前四年多的成長情況,和對這之後四年 (到2027) 的預期」,相信「到 2027 年,模型將能夠完成人工智慧研究員/工程師的工作,是非常合理的」。
- 他認為:透過計算OOM,模型可以預見地、可靠地變得更好,因此透過計算OOM也可以推斷出未來模型改進的幅度。這是他預期到 2027 年,在 GPT-4 之上還會出現 GPT-2 到 GPT-4 大小的跳躍的原因。
- 作者強調,雖然許多人低估了這一趨勢,但事實上,深度學習的進展一直在超出預期。他們建議讀者"相信趨勢線",並提醒我們不要重複過去低估AI進展的錯誤。
備註:OOM代表Order of Magnitude(數量級) → 1 OOM = 10倍增長 / 0.5 OOM ≈ 3倍增長
下圖的 Y 軸表示有效計算能力 (採對數刻度將 GPT-4 設為 1),可以看到圖中標記了不同 GPT 模型的相對計算水平,分別為:GPT-2 約 10^-6、GPT-2 約 10%-3、GPT-4 為 1。圖中並預測了 2023 年之後的計算能力將持續呈指數成長,預計到 2027~2028 的有效計算能力可能達 GPT-4 的 10^6~10^8 倍。作者推估這一水平的計算能力可以實現 “自動化AI研究員/工程師" 的能力。
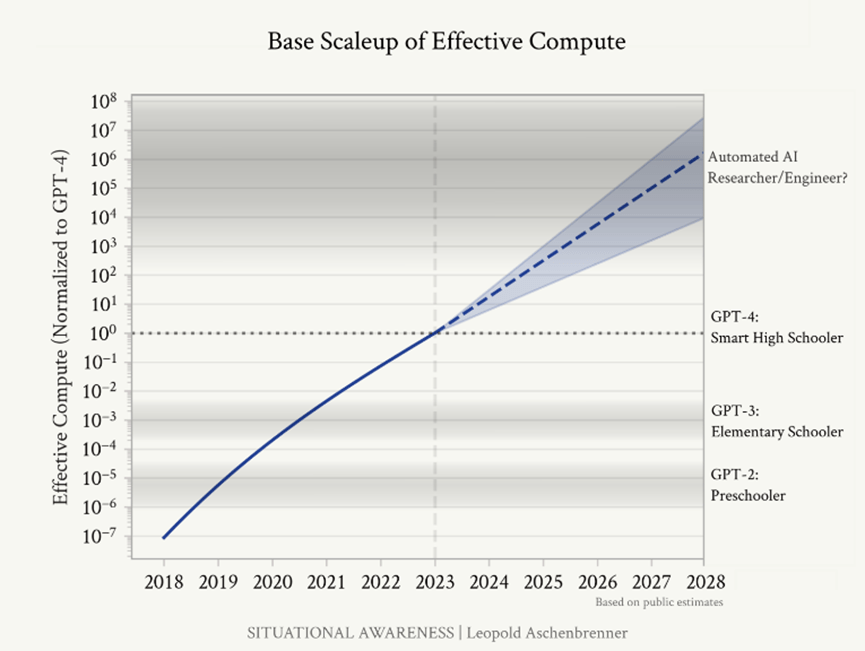
回顧過去AI發展
過去十年深度學習的進步速度十分驚人,許多領域正在迅速達到或超過人類水準。

GPT-2到GPT-4僅僅花了約4年,就創造了從學齡前到高中程度的能力飛躍:
- GPT-2 (2019):相當於學齡前兒童,勉強能生成一些連貫的句子。GPT-2甚至無法做簡單的加減法。
- GPT-3 (2020):相當於小學生水準。GPT-3在給予少量示例後,就能完成一些簡單有用的任務,像是文法修正或簡單算術。這是第一個在商業上有一些實際應用的模型。
- GPT-4 (2023):相當於聰明的高中生。GPT-4可以撰寫複雜的程式碼並進行debug,可以就難解的主題寫出有洞見的論文,能處理高中程度的競賽數學題。GPT-4已經可以協助人們完成日常工作,像是寫程式或修改文章草稿。
作者認為這主要歸功於三大驅動力:
- 計算能力 (Compute):用於訓練AI模型的硬體算力,通常以FLOPS(每秒浮點運算次數)來衡量。
- 演算法效率 (Algorithmic efficiencies):在相同硬體條件下,通過改進算法來提高模型性能或減少所需資源。
- “解除限制"增益 (“Unhobbling" gains):通過消除模型的明顯限制來釋放潛在能力。
我的想法:用這樣的分類說明指數型成長還不錯。硬體算力大家容易理解,後兩者則是將軟體拆分成兩個組成,分別是透過算法改進來提高模型性能或減少所需資源的方式,像是演算法本身的優化還有NVIDIA提供連結硬體的軟體優化都在這個類別中;另一個「解除限制的增益」則是很好的說明了其實如果要真正可以跳一級的採用,要用某種方式突破瓶頸,這是為什麼RLHF才讓ChatGPT被拿上檯面、轟動全世界。
詳細說明三大驅動力
1. 計算能力的提升(Compute):~0.5 OOM/年
計算能力的增長是驅動AI進步的關鍵因素之一。近年來,我們見證了AI訓練所用計算資源的爆炸性增長,這種增長遠遠超過了摩爾定律的預測。
從GPT系列模型計算能力的演進速度:
- GPT-2 (2019): ~4e21 FLOP
- GPT-3 (2020): ~3e23 FLOP (增長約2 OOM)
- GPT-4 (2023): 8e24 到 4e25 FLOP (再增長約1.5-2 OOM)

在短短4年間,從GPT-2到GPT-4,訓練所需的計算量增加了約3000-10000倍。這種增長速度遠遠超過了傳統的摩爾定律(每18-24個月翻倍)。(以這四年計算能力每年提升0.5OOM來看,成長約是摩爾定律的五倍)
GPT-2到GPT-3的飛躍特別引人注目。在僅僅一年的時間裡,計算量增加了將近100倍。這種巨大的躍升反映了AI研究界和產業界對大規模語言模型潛力的認識,以及他們願意投入前所未有的資源來推動這一領域的發展。(曾經沒有人接受在一個模型上花費一百萬美元,而現在這只是零頭!)
GPT-3到GPT-4的發展則展示了一個更加持續和穩定的增長趨勢。儘管增長速度相對放緩,但仍然保持了驚人的每年0.5-0.7 OOM的增長率。這表明,即使面臨著技術和資源的挑戰,AI領域仍在不斷突破極限,持續擴大計算規模。
從廣義上講,這只是長期趨勢的延續。在過去的十五年裡,主要是由於投資的廣泛擴大(以及以 GPU 和 TPU 形式用於 AI 工作負載的專用晶片),用於前沿 AI 系統的訓練計算以每年約 0.5 OOM 的速度增長。
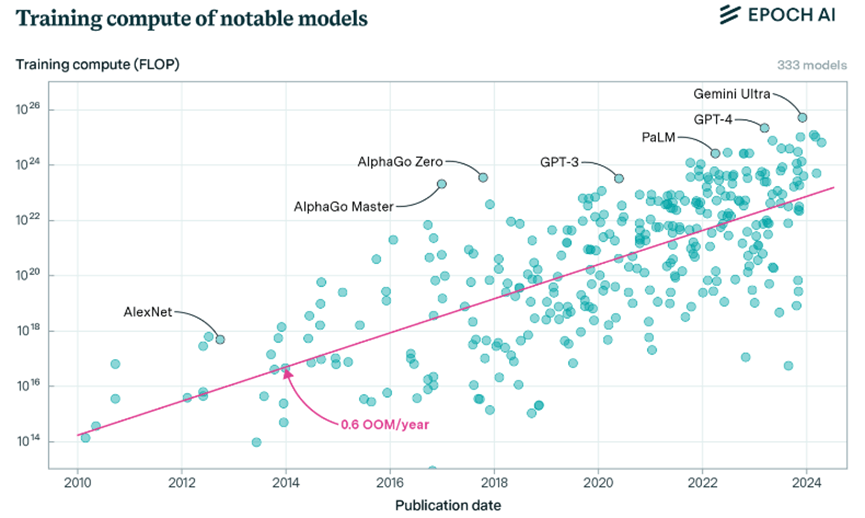
成長的驅動因素:
- 硬體技術的進步:GPU和TPU等專門為AI workload設計的芯片不斷推陳出新,性能大幅提升。以及專用於訓練大規模模型的數據中心。
- 平行計算技術的發展:更先進的分佈式計算技術使得同時協調數萬個GPU進行訓練成為可能。
- 大規模投資:過去四年內,訓練 AI 模型所使用的計算資源急劇增加,這主要是由於大量的資金投入,用於訓練模型的計算機變得更大更強。
基於這一趨勢,作者預測未來幾年的計算能力會延續現有的成長,預計每年增加約0.5OOM。到2030年,我們將擁有相當於現在GPT-4訓練集群100000倍的計算能力。這種規模的計算能力可能會帶來質的飛躍,使得當前被認為是不可能的AI任務變為可能。
而計算能力急遽增加帶來的挑戰有以下幾點:
- 能源消耗:估計到2028年,僅僅一個頂級AI訓練集群就可能消耗相當於一個中等規模美國州的電力。這對能源基礎設施和環境都將造成巨大壓力。
- 成本:儘管單位計算成本在下降,但總體投資規模仍在迅速攀升。預計到2028年,單個訓練集群的成本可能達到數百億美元。
- 數據瓶頸:隨著模型規模的增長,獲取足夠高質量的訓練數據變得越來越具挑戰性。
2. 演算法效率的改進(Algorithmic efficiencies):~0.5 OOM/年
算法效率的提升是推動AI進步的另一個關鍵因素。與計算能力的增長相比,算法效率的改進可能是同樣重要的進步驅動力,卻被大大低估了。
許多演算法改進起到了“計算乘數”的作用,能夠在統一的計算規模上表現出更大的有效計算力。通過改進演算法,可以在不增加硬體資源的情況下,使得我們以更少的資源顯著提升模型的性能。
我的補充:NVIDIA CEO 黃仁勳有說過「軟體對於加速計算至關重要,沒有軟體就無法開拓新市場和支援新應用。軟體是加速計算和通用計算的根本區別,大多數人花了很長時間才理解,但現在人們已經明白軟體的關鍵作用。」
算法效率的演進:過去十年間,我們見證了算法效率的顯著提升
- 根據 EpochAI 的估計,從 2012 年到 2023 年,語言建模的算法效率提升了約 4 個 OOM(數量級)。
- 這意味著,相比 2012 年,2023 年的模型可以用 10000 倍更少的計算資源達到相同的性能。
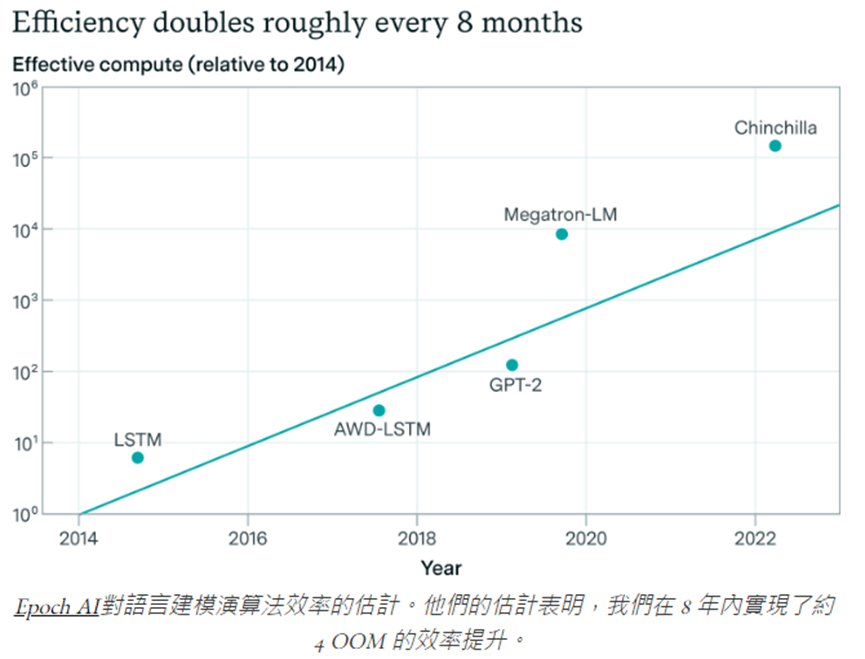
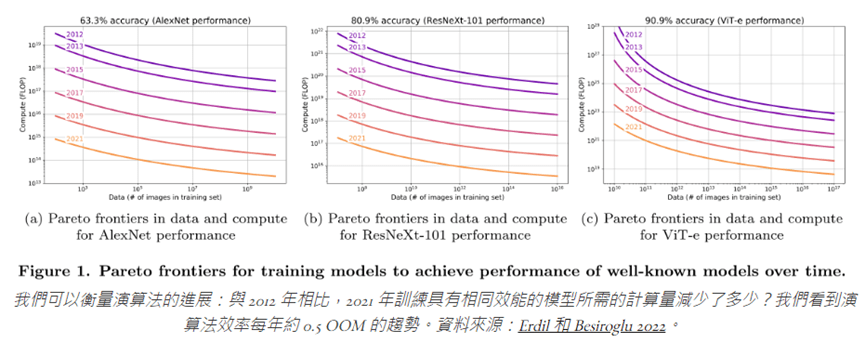
這種進步帶來模型更優,但成本與效率更高的具體實例:
- GPT API成本大幅降低:GPT-4在發布時的API成本與GPT-3相似,但性能卻有了巨大提升,這意味著算法效率的提升抵消了更大規模訓練帶來的成本增加。而隨著GPT-4o 的發布,GPT-4 等級模型的 OpenAI 價格又下降了 6 倍/4 倍(輸入/輸出)。
- Gemini 1.5 Flash:這個最新的模型展示了驚人的效率提升。它的性能接近GPT-4,但推理成本降低了85-57倍。這種級別的效率提升可能徹底改變AI的應用場景。
- 我的補充:Claude 3.5 Sonnet也是效能更優、API殺到超甜流血價的超經典代表!(關鍵是扮演著讓OpenAI有競爭對手壓力的角色)
算法效率的提升的驅動因素:
- 新的模型架構:例如Transformer架構的各種改進版本,如MoE(Mixture of Experts)。
- 更有效的訓練技術:如混合精度訓練,允許在不損失精度的情況下使用更低的數值精度。如NVIDIA cuDNN使訓練過程變得更加高效,達到硬體-軟體協同優化,可以在相同的硬體上實現更快的訓練速度。
- 優化算法的改進:如AdamW優化器對Adam的改進。
- 數據處理和利用效率的提高:如更好的數據清洗和採樣策略。
算法效率提升帶來的影響:
- 降低了 AI 研究的門檻:更高的效率意味著更多的研究者和組織可以參與到AI的開發中來。
- 擴大了 AI 的應用範圍:更高效的算法使得在資源受限的設備(如手機)上運行複雜AI模型成為可能。
- 加速了 AI 的發展速度:每一次算法效率的提升都相當於給整個領域帶來了一次"免費"的硬體升級。
展望未來,作者認為有理由相信算法效率還有很大的提升空間。許多研究者認為,我們當前的深度學習方法仍然遠不如人腦效率。這意味著,通過持續的創新,我們很可能會看到算法效率的進一步大幅提升。
3. 「解除限制」的增益(”Unhobbling” gains)
“解除限制"增益是指通過消除模型的明顯限制來釋放其潛在能力的技術,是最難量化但同樣重要的改進類別。
這些技術不直接提高模型的原始能力,而是通過巧妙的方法使模型能夠更好地發揮其已有的能力:像是根據人類回饋進行強化學習 (RLHF),首次使模型對真人可用且有用,造成ChatGPT的爆炸發展。最初的InstructGPT 論文對此進行了很好的量化:就人類評分者偏好而言,RLHF 的小模型相當於非 RLHF >100 倍的大模型。
主要"解除限制"的技術:
- 人類反饋強化學習(RLHF): RLHF 的引入是一個重要的轉折點。它使得模型能夠更好地對齊人類的偏好和意圖。一項研究表明,經過RLHF處理的小型模型在人類偏好方面的表現可以等同於未經處理的 100 倍 larger 模型。這種效果相當於在模型能力上獲得了 2 個 OOM 的提升,而且幾乎是"免費"的。
- 思維鏈(Chain of Thought, CoT)提示: CoT 的引入極大地提高了模型在複雜推理任務上的表現。例如,在數學問題上,使用 CoT 可以帶來超過 10 倍的性能提升。這種提升尤其顯著,因為它不需要重新訓練模型,只需要改變提示的方式。
- 工具使用能力: 讓 AI 能夠使用外部工具(如計算器、網絡搜索等)大大擴展了其能力範圍。例如,在 HumanEval(一個程序編碼基準測試)上,具備工具使用能力的 GPT-3.5 甚至可以超過未使用工具的 GPT-4。
- 上下文長度的擴展: 上下文長度的擴展使模型能夠處理更長的輸入,從而處理更複雜的任務。從 GPT-3 的 2k tokens 到 GPT-4 發布時的 32k,再到 Gemini 1.5 Pro 的 1M+,這種擴展極大地增加了模型的實用性。
解除限制的技術影響十分巨大
- Epoch AI 的調查發現,這些技術通常可以在許多基準測試上帶來 5-30 倍的有效計算增益。
- METR 的研究顯示,在他們的代理任務集上,同一 GPT-4 基礎模型的表現從 5% 提升到近 40%。
累積效應的加乘效果
作者認為計算能力、算法效率和"解除限制"技術的進步不僅會獨立貢獻,還會相互促進,產生更大的綜合效果。因此估計,我們可能會在 4 年內再次看到類似 GPT-2 到 GPT-4 那樣的質的飛躍。
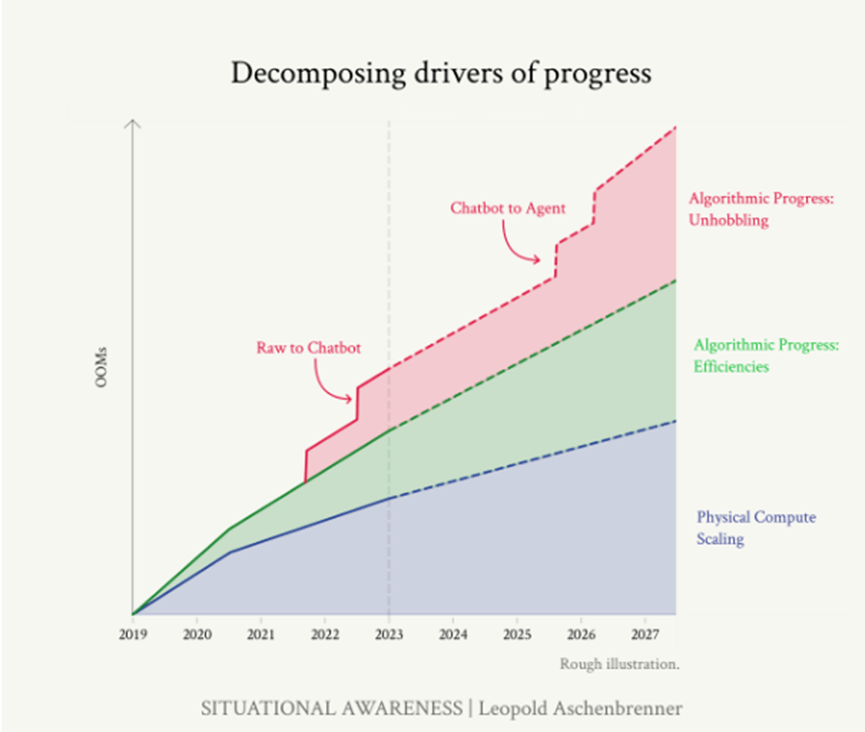
綜合效果與未來推論
在分析了計算能力、算法效率和"解除限制"增益這三個關鍵因素後,作者試圖將它們綜合起來,以預測未來 AI 發展的軌跡。
回顧過去四年的綜合效果(GPT-2 到 GPT-4):
- 總體有效計算能力增長:約 4.5-6 OOM(數量級)
- 能力提升:從"幼兒園水平"到"聰明高中生水平"
這種進步的速度是驚人的。在短短四年內,AI 系統從僅能生成簡單、有時連貫的文本,發展到能夠通過高中和大學入學考試,解決複雜的數學問題,甚至編寫複雜的計算機程序。

進行未來四年的預測(2023-2027)
由於以下幾點關鍵假設,作者認為未來四年有效算力增長約 5 OOM,可能使AI達到超越人類專家、潛在達到 AGI 水平:
- 計算能力增長將持續:預計每年約 0.5 OOM,四年累計 2 OOM。
- 算法效率提升不減:預計每年約 0.5 OOM,四年累計 2 OOM。
- “解除限制"增益將帶來額外提升:雖然難以精確量化,但預計會帶來顯著的額外能力提升。

而上述推理邏輯來自於以下幾點:
- 趨勢外推:假設過去觀察到的增長趨勢在短期內會持續。這是基於 AI 領域持續的大量投資和創新。
- 協同效應:認為計算能力、算法效率和"解除限制"技術的進步不僅會獨立貢獻,還會相互促進,產生更大的綜合效果。
- 突破性創新的可能性:考慮到 AI 研究的快速發展,可能會出現類似 Transformer 架構那樣的突破性創新,帶來超出線性預期的進步。
- 產業推動力:隨著 AI 在各行各業的應用越來越廣泛,來自商業和政府的投資可能會進一步加速發展。
若是真的,屆時將對勞動力市場、科學研發、社會經濟變革帶來全新的挑戰。而政府在此的監管變化也會影響相關技術的發展進度。
AGI 的自我加速發展
一旦我們獲得了 AGI (人工通用智能),我們就不會只有一個 AGI。相反,AGI 的出現可能會引發一個快速的自我增強和擴散過程,導致多個AGI系統的快速湧現。這種現象可能會 dramatically 加速 AI 的發展進程,遠超我們當前的預期。
AGI 的自我加速機制:
- 自動化 AI 研究:AGI 系統將能夠自主進行 AI 研究,包括設計新的算法、架構和訓練方法。這可能會大大加快研究速度,因為 AGI 可以 24/7 不間斷工作,並且處理信息的速度遠超人類。
- 並行化和規模化:我們可能不會只運行一個 AGI 實例,而是同時運行成千上萬個。根據作者的計算,到2027年,我們可能有能力運行相當於1億名人類研究者的 AGI 系統。
- 超人類速度:這些 AGI 系統不僅在數量上超過人類,在工作速度上也可能遠超人類。作者認為通過一些權衡,我們可能讓這些系統以人類速度的 100 倍運行。
- 累積經驗和知識:每個 AGI 實例的學習和發現都可以被即時共享和整合到其他實例中,創造一個空前的知識和經驗積累速度。
基於這些因素,他推測AGI可能會導致以下加速效果:
- 算法效率飛躍:AGI 可能在短時間內實現當前需要數年才能達到的算法突破。作者估計,僅僅一年的AGI研究可能就能壓縮十年的人類算法進展,相當於 5+ OOM(數量級)的效能提升。
- 新範式的快速出現:AGI 可能會快速探索和發現全新的 AI 範式,遠超我們當前的深度學習方法。
- 硬體設計優化:AGI 可能會設計出更高效的 AI 專用硬體,進一步提升計算能力。
- 跨學科突破:AGI 的研究不僅限於 AI 領域,還可能在物理學、生物學等領域帶來突破,間接促進AI的發展。
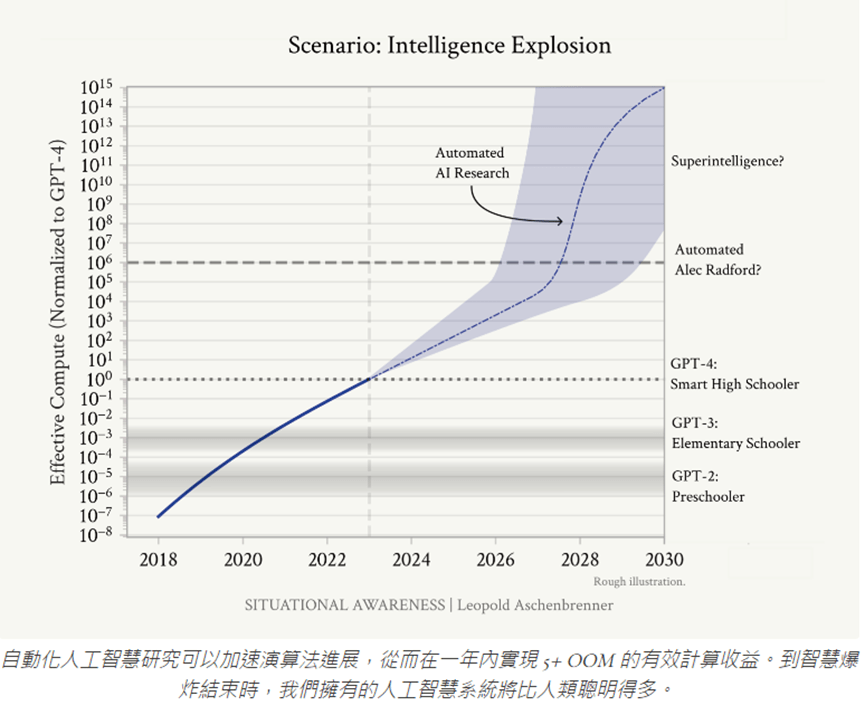
我的想法:他的意思就是當突破一個關鍵位置時,會再出現一次 OOM 加速!(這是他作為樂觀者的想法)對我而言,其實聽起來是合理的,但是站在現在這個位置就去做這麼大的夢還有點太遠,我比較傾向且看且走。
現在我認同的是:站在有效算力 OOM 持續成長的角度,模型效能很有可能再一次大幅度進步。至於是否達 AGI?我個人是覺得除非出現新模型,否則以目前的主流演算法 (Transformer) 根本不可能。至於是否觸碰到 OOM 再加速的點?到時可能會有這個想像,但政府也很有可能出手,畢竟屆時這台指數成長的列車將以光速成長,很可能危害到國家安全。
但無論如何可以確定的是,當有效算力呈現指數型成長時,持續研發 AI 模型的公司會有壓力要盡快推出最優秀模型,以免被競爭者淘汰,畢竟現在看起來,還是一場贏者全拿的遊戲。
Racing to the Trillion-Dollar Cluster : AI 基礎設施的未來
作者認為,我們正處於一個前所未有的技術資本加速時期,這將重塑全球產業格局,他將現在的AI基礎設施建設比作歷史上的重大工業化運動:
- 類比於19世紀的鐵路建設:在1841年至1850年間,英國私人鐵路投資總額達到當時GDP的約40%。
- 類比於20世紀末的互聯網基礎設施建設:1996年至2001年間,電信公司投資了近1兆美元(按今日價值計算)來建設互聯網基礎設施。
- 這不僅是一場技術競賽,更是一場國家間的競爭:美國、中國等主要國家都在積極投入資源發展AI基礎設施。中東國家也在利用其能源優勢,試圖在AI領域佔得一席之地。
- 目前AI基礎設施的建設速度和規模都遠超過去:從小規模實驗到佔用整個數據中心的大型語言模型,僅用了幾年時間。
基於上述趨勢,他對未來幾年投資規模做出大膽預測:「投資規模將呈現指數及成長」
- 短期預測(2024-2026):
- 到 2024 年,AI 總投資可能達到 1500-2000 億美元。
- 到 2026 年,主要科技公司(如谷歌、微軟)的 AI 產品年收入可能達到 1000 億美元。
- 中期預測(2027-2028):
- 到 2027 年,AI 總投資可能突破每年 1 兆美元。
- 這一數字相當於美國 GDP 的約 3%,遠超曼哈頓計劃和阿波羅計劃在巔峰時期的投資比例(約為 GDP 的 0.4%)。
作者論證這些數字合理性的根據:
- 以微軟為例,如果其 3.5 億付費 Office 用戶中有三分之一願意為 AI 附加功能每月多付 100 美元,那麼僅此一項就能帶來超過 1000 億美元的年收入。
- 考慮到 AI 可能自動化大量白領工作,這些投資回報率可能會非常高。
作者對 AI 收入成長是非常樂觀的,他認為 2023/8 Open AI 年化收入達 10 億美元、2024/2 年化收入達 20 億美元,代表每六個月可以翻倍。如果這種趨勢持續,到 2024 年底或 2025 年初,主要 AI 公司的年收入可能達到 100 億美元以上。他認為,這種快速增長的收入將繼續推動更大規模的投資。
我的想法:這很顯然要且看且走,我目前看好對 OpenAI 和 Anthropic 這種掌握 AI 大模型的廠商收入增速,認同他認為每六個月可以翻倍的期待;但另一方面由於微軟的Copilot滲透率目前還看不到很明確的加速,所以對其他CSP大廠的業務助益,可能還需要觀察。(但我比較樂觀的是,我認為更好用的大模型是關鍵,當模型更好用的時候,就有可能出現一個應用與價格的甜蜜點,促使終端需求大幅爆炸,而微軟 Copilot 目前用 GPT-4 還不太行阿… 如果採用新的 GPT-4o 模型可能會更讚!)
會帶來的問題:能源需求大幅上升,可能導致能源嚴重不足(美國電力生產在過去十年只成長5%)
- 2026 年的集群可能需要約 1 GW的電力,相當於一個大型核反應堆或胡佛大壩的輸出。
- 2028 年的集群可能需要約 10GW,相當於一個中小型美國州的用電量。
- 2030 年的 1 兆美元集群可能需要 100GW,超過美國當前電力生產總量的 20%。
作者附錄的有趣想法:這十年要嘛成功,要嘛蕭條
根據OOM看,這十年是發展AI的最佳時機,要嘛成功,要嘛蕭條
- 作者曾經對 AGI 短期內實現持懷疑態度,認為不應過分集中於這十年。但作者現在改變了看法,認為我們應該關注計算能力的數量級 (OOM) 增長,而不是年份。
- 這十年我們正在快速增加計算能力的數量級。作者估計 4 年內會增加約 5 個數量級,整個十年會增加超過 10 個數量級。
- 這種快速增長主要來自三個方面:
- 資金投入大幅增加 (從百萬美元模型到可能的千億美元集群)硬體性能快速提升 (專用 AI 晶片的發展)
- 演算法進步 (大量研發投入帶來的改進)
- 但這種快速增長可能在 2030 年代初期就會放緩,之後進展會慢得多。因此他認為如果這十年的快速發展不能實現 AGI,那麼之後可能需要很長時間才能實現。
我的想法:整體來說是非常有趣的報告,站在有效算力提升會帶來更智能模型的假設下,這是信奉者認為可能成真的巨大藍圖。我其實覺得很有機會,至少在未來四年,因為各家大幅投入人力與資金,再出現 AI 模型的巨大飛越是可以期待的,而這樣的假設又有可能推動應用蓬勃發展,是有可能再回頭進一步推升需求。
我比較擔憂的部分可能是若真的出現更進一步的智能模型,政府角色就會變得很關鍵,是否出來做些打壓的動作將成為後續需要留意的。只是在那之前可以確認「主權 AI」是新時代各國角力不可或缺的一環,應該會對 NVIDIA 硬體客戶分散化帶來不小的助益。
免責聲明:本文章內容僅供投資人參考,無任何推薦與買賣邀約之情事,投資人應獨立審慎判斷,自負買賣風險謹慎投資,本網站不負任何法律責任。
NVIDIA 隨手記文章:
- NVIDIA (NVDA) 2023Q4 財報:推理占比飆升至 40%,AI 工廠正在挖深護城河! (2024-04-10)
- NVIDIA (NVDA) 2024Q1 財報:軟體賦能硬體,推論與訓練的算力需求皆顯著成長 (2024-05-24)
- 美銀論壇整理:NVDA 看好 Token serving 與推論業務帶來的龐大市場 (2024-06-07)
- NVIDIA 軟體戰略全面解析:建構未來幾年內難以撼動、既寬且深的護城河 (2024-06-19)
- 回顧去年 NVIDIA 論壇:長期軟體營收可望過半,創造公司成長的下個飛輪 (2024-06-25)
AI 市場報告整理 – 隨手記文章:
- 整理:從史丹佛大學 2024 AI 報告看長線趨勢 (2024-05-08)
- 微軟 CEO Nadella 專訪解讀 AI 戰略:把握歷史性機遇,推進系統創新和平台構建 (2024-05-30)
- 「業內人士看 GenAI 發展」之一:從 OOM 推算人工智慧的指數型發展,預測 2027 年將迎來大突破 (2024-07-03)
- 「業內人士看 GenAI 發展」之二:AI 推理成本將隨時間大幅下滑,創造應用落地甜蜜點? (2024-07-05)
- 「業內人士看 GenAI 發展」之三:Anthropic CEO 暢談 AI 未來 (2024-07-05)

你必須登入才能發表留言。